
AI Agent Coding Patterns
- 박준성 박사: Univ. of Iowa 종신교수, 삼성SDS CTO, KAIST 초빙교수

- Mar 13
- 37 min read
Updated: 7 days ago
The Pragmatic Summit in February 2026 (https://www.pragmaticsummit.com/) reports that 93% of software developers use AI coding tools, saving an average of 4 hours a week; 27% of code is AI-authored; and more than 50% of developers in advanced companies use AI coding agents every day. (https://www.youtube.com/watch?v=LOHgRw43fFk) AI agent coding has become the most efficient way to build business applications.
The U.S. Bureau of Labor Statistics reports that software developer roles declined only 0.3% over 2024–25 and will grow 15% from 2024 to 2034, which is much faster than the average for all occupations. (https://www.bls.gov/ooh/computer-and-information-technology/software-developers.htm)
Why do we need more developers while AI coding tools can improve their productivity in coding?
First, the demand for AI-powered applications developed with AI coding agents is exploding, offsetting productivity gains and requiring many developers capable of coding with AI agents. Gartner predicts that by 2026, more than 80% of enterprises will have tested or deployed GenAI-enabled applications — up from less than 5% in 2023. (https://www.gartner.com/en/experts/top-tech-trends-unpacked-series/harness-democratized-generative-ai-transform-your-business)
Second, software developer roles involve stakeholder communication, requirements analysis, architectural design, quality assurance, incident management, performance management, capacity planning, and much more—all of which require an understanding of environments, collaboration, and judgment that an AI coding agent cannot handle on its own.
So, no matter how far AI agent coding advances, software developers need to understand the business strategy and requirements and be capable of software engineering to be involved effectively with AI coding agents. AI coding agents can amplify developers' capabilities, but cannot replace them.
A pattern is a reusable, named solution to a commonly recurring problem within a given context. To build a successful business application via agent coding, we should apply well-known patterns for IT-enabled business transformation (a.k.a. digital transformation). To build high-quality software via agent coding, we should stick to proven software engineering patterns. Since an AI coding agent is a type of AI agent, and an AI agent is built on a generative AI foundation model, an AI coding agent should inherit the growing set of patterns for generative AI agents, which in turn should inherit the patterns for developing successful generative AI applications.
We will first look into the patterns for digital transformation as applied to AI transformation(AX), then generative AI patterns, AI agent patterns, software engineering patterns as applied to agent coding, and finally agent coding patterns.
I. AI Transformation(AX) Patterns
There are well-known best practices for IT-enabled business transformation, or digital transformation (DX), that utilize new technologies such as cloud computing, big data, IoT, AI models, and AI agents. These DX patterns can result in significant improvement in business performance. Developers should apply the DX patterns, a.k.a. AX patterns, when using agent coding to develop AI agents for business management and operations.
Plan-Do-Check-Act (PDCA) Cycle
As with all business transformation efforts, DX enabled by agent coding should also follow the Deming Cycle. Other similar patterns that developers can apply include the BPM Cycle (Design, Model, Execute, Monitor, and Optimize), 6 Sigma (Define, Measure, Analyze, Design, Optimize, and Verify: DMADOV), Design Thinking (Empathize, Define, Ideate, Prototype, Test, and Implement), and Lean Startup (Build, Measure, and Learn). (https://www.kosta-online.com/challenge-page/requirement-analysis; https://www.kosta-online.com/post/ai-agent-sucess-factors) Several AI agent coding patterns (explained below) support this AX pattern: Explore-Plan-Code, ReAct, Iterative Human-in-the-Loop, Autonomous Monitoring-Evaluation-Learning Closed-Loop Feedback, and Analytics and Monitoring.
Use Cases with a Clear Value Proposition
Identify AI agent coding use cases that deliver a strong value proposition to stakeholders. (https://www.kosta-online.com/challenge-page/use-case-analysis-and-realization)
Low-variance, high-standardization workflows, such as mainstream operational processes, tend to be tightly governed and follow predictable logic. In these cases, agents based on nondeterministic LLMs (Large Language Models) could add more complexity and uncertainty than value. (https://www.kosta-online.com/post/ai-agent-hype-and-reality) By contrast, high-variance, low-standardization workflows could benefit significantly from LLM-based agents. For example, tasks demanding information aggregation, verification checks, and compliance analysis are where agents can be effective. (https://www.kosta-online.com/post/ai-agent-sucess-factors)
AI agent coding platforms should create clear value for mechanical boilerplate coding. They also create value for high-level, abstract tasks, such as requirements specification and architectural design, although humans must intervene and own this. Several AI agent coding patterns (explained below) support this AX pattern: Macro Prompts, Specification-Driven Development, Image as Spec, Spec-to-Scaffold Automation, and Explore-Plan-Code.

Enterprise Architecture (EA)-based Strategy Plan
Since the early 2000s, leading companies and governments have adopted Enterprise Architecture (EA) as the method for business and IT strategy planning. EA encompasses business process management (BPM), metadata management (MDM), and enterprise service-oriented architecture (SOA), which we explain below. (J. W. Ross , et al. Enterprise Architecture As Strategy: Creating a Foundation for Business Execution, Harvard Business School Press, 2006; https://www.kosta-online.com/challenge-page/enterprise-architecture-design)
EA Governance should be the mechanism for classifying which processes are safe for LLM agent automation, standardizing verification checkpoints and quality gates, and auditing agent behavior against enterprise compliance requirements. Without EA governance, the risk of nondeterminism is unmanaged at the enterprise level. DX enabled by agent coding, if planned outside an EA framework, risks creating shadow IT at scale — powerful, fast-moving, but ungoverned and strategically incoherent
DX enabled by agent coding should be planned and implemented within the EA Framework. (https://www.kosta-online.com/post/ai-agent-sucess-factors) Several AI agent coding patterns (explained below) support this AX pattern: Context Perception and State Management, Policy and Guardrails, and Context Engineering.

Business Process Management (BPM)-based Process Innovation
Business Process Management (BPM) is a discipline and set of technologies used to analyze, model, redesign, automate, monitor, and improve business processes within an organization. BPM applies Business Process Reengineering (BPR) to end-to-end processes in an enterprise. BPM should precede all innovative application development.
Business Process Model and Notation (BPMN) 2.0 is the de facto standard language for modeling business processes. A conceptual-level BPMN process model can be automatically converted to an executable process in a Business Process Management Suite (BPMS) such as Pegasystems, Appian, IBM Business Automation Workflow, Microsoft Power Automate, and AWS Step Functions.
Agentic AI efforts that fundamentally reimagine entire workflows are likely to deliver better results. Understanding how agents can help with each step in the workflow is the path to value. People will still be central to getting the work done, but now with different agents, tools, and automations to support them. (https://www.mckinsey.com/capabilities/quantumblack/our-insights/one-year-of-agentic-ai-six-lessons-from-the-people-doing-the-work#/)
AX enabled by agent coding should start with identifying the end-to-end process the company wants to reengineer. (https://www.kosta-online.com/challenge-page/bpmn-based-business-process-design-and-implementation) On the other hand, agent coding fundamentally changes the software development lifecycle, requiring new specific roles, skills, and techniques at each step of the development process.
Several AI agent coding patterns (explained below) support this AX pattern: Executable Process Model, Rules Management, Agentic Workflow, Agentic Engineering Workflow, State Management, Policy and Guardrails, Context Engineering, Role Switching, and Agent Teams.

Metadata Management(MDM)-based Semantic Model
Semantic models are crucial for software application development. Firms should establish company-wide metadata management to maintain high-quality semantic models. (https://www.kosta-online.com/challenge-page/data-engineering)
Semantic models are essential for contextual understanding, relationship mapping, intent inference, intelligent code generation, and advanced debugging in agent coding. Three layers of semantic models should align: Domain Semantic Models, Process Semantic Models, and Codebase Semantic Models.
Several AI agent coding patterns (explained below) support this AX pattern: Domain-Driven Design (DDD), State Management, and Context Engineering.

Enterprise Service-Oriented Architecture (SOA)
Since the middle of the 2000s, leading companies and governments have adopted SOA across their software applications. (https://learning.dell.com/content/dam/dell-emc/documents/en-us/KS2009_Hariharan-Service_Oriented_Architecture_(SOA)_and_Enterprise_Architecture_(EA).pdf) DX applications developed using agent coding should also be in SOA. Agent coding platforms themselves are internally SOA and interact with external systems via SOA APIs. (https://www.kosta-online.com/post/ai-first-and-api-first-strategies; https://www.kosta-online.com/post/ai-agent-system-is-soa) Several AI agent coding patterns (explained below) support this AX pattern: Agent in SOA, Bounded Context Injection, and API Integration.
II. Generative AI Patterns
Generative AI(GenAI) patterns are recurring design approaches for building GenAI applications—ways to make LLM-based systems more useful, reliable, safe, and production-ready. They cover things like how you ground the model, how you evaluate it, how you add memory or tools, and how you control outputs. All of the GenAI patterns are inherited by the GenAI agent patterns explained below, which in turn are inherited by the GenAI agent coding patterns explained below.
Foundation Models
A foundation model is a large pretrained model that serves as the base for many different downstream AI applications. It is trained on large-scale, broad data, usually using self-supervised learning, so it can be adapted to tasks such as chat, code generation, summarization, image creation, question answering, agentic AI, and agentic coding.
Parameter-Efficient Fine-Tuning (PEFT)
PEFT is a way to adapt, customize, or fine-tune a foundation model for a new domain or task by training only a small set of additional or selected parameters, while keeping most of the original model frozen. Low-Rank Adaptation(LoRA), Prefix Tuning, and Prompt Tuning are common examples of PEFT.
Prompt Engineering
Structuring, designing, and refining input text (prompts) to guide GenAI models to produce accurate, relevant, high-quality outputs.
The following AI agent coding patterns (explained below) support this AI agent pattern: Macro Prompts, Specification-Driven Development, and Image as Spec.
Prompt Chaining
Break complex tasks into smaller, sequential steps, where the output of one prompt serves as the input for the next. It improves accuracy, allows for complex reasoning, and enhances controllability by tackling problems in a structured, modular way.
AI-Assisted Creative Ideation
Vibe Engineering is a GenAI pattern for prompt-first, feedback-driven creation. The main idea is to use natural-language intent, rapid iteration, and model-generated output to shape software or other artifacts.
In vibe engineering, the human describes the desired outcome in plain language, the GenAI system drafts something, and the human refines it through feedback loops. The emphasis is on flow, speed, and collaboration rather than manual line-by-line implementation.
Embeddings
Embeddings in generative AI are numerical vector representations of text, code, images, or other data that capture semantic meaning rather than exact wording or syntax. They convert information into high-dimensional coordinates so that similar meanings are located close together, related concepts cluster together, and semantic search becomes possible.
Embeddings enable Retrieval-Augmented Generation (RAG), context matching, knowledge base navigation, recommendation, and clustering in GenAI prompting. They enable searching knowledge bases, retrieving relevant documents, understanding prior cases, matching tasks to tools, tracking context across workflows, and coordinating with enterprise systems in GenAI agents. They enable understanding of the codebase, semantic code search, bug diagnosis, and refactoring in agentic coding.
To use embeddings effectively in GenAI prompting, humans need to curate knowledge sources, chunk content properly, generate embeddings using embedding models and vector DBs, add metadata, design retrieval logic, and validate output quality. In agentic AI, they may build semantic enterprise memory, such as SOPs, APIs, and tool registries; define operational metadata, such as tool permissions, workflow states, and policies; integrate embeddings into task planning, tool selection, and workflow orchestration; and monitor the output. In agentic coding, they may index the codebase, structure repositories, embed code snippets, store bug patterns and reusable components, and review architecture and code.
Common tools that humans use include: vector DBs, knowledge graphs, data catalogs, RAG frameworks, MCP registries, and observability platforms.
Memory / State Management
Memory/state management in GenAI applications is the set of techniques that enable an AI system to retain useful context, track what’s happening in the current session, and reuse important facts later, rather than acting as if every turn is brand new. With good memory management, the GenAI application feels more coherent, more personalized, and better suited to long-running tasks such as planning, support, or multi-step workflows.
There are three types of memories: (1) Short-term context keeps the immediate conversation state, like the last few messages or the current task step. (2) Working state tracks active variables, decisions, tool results, and workflow progress during a session. (3) Long-term memory stores stable facts such as user preferences, project details, or prior decisions so the system can recall them in future sessions.
Retrieval-Augmented Generation (RAG)
RAG is a GenAI approach that combines a model with an external knowledge source, enabling the model to retrieve relevant information first and then generate a better answer. See the RAG service in the SOA architecture of GenAI applications shown below.
A RAG system usually does three things: (1) Retrieval finds relevant documents or passages from a database, knowledge base, or search index. (2) Augmentation adds the retrieved context to the user’s prompt. (3) Generation lets the LLM produce the final answer using both its training and the retrieved context.
Instead of relying solely on its internal training data (which might be outdated or lack specific context), the model can look up relevant information in real-time to provide more accurate and grounded answers.

Policy and Guardrail
Policies and guardrails in GenAI applications are the rules and controls that keep the model’s behavior inside acceptable boundaries. They are essential, proactive safety mechanisms — technical, operational, and ethical constraints — designed to ensure GenAI applications operate within defined security, legal, and organizational standards.
In the above diagram of GenAI application architecture in SOA, the policy & guardrail service is invoked to verify that the user prompt does not violate the constraints, and is invoked again after the prompt is refined with the help of RAG, MCP, and A2A services before invoking the LLM service to get an answer.
Policies and guardrails prevent harmful content, mitigate risks such as prompt injection and data leakage, and maintain real-time reliability and compliance in AI behavior. This service is also an essential component of the Generative AI Agent Architecture (shown below). (https://www.kosta-online.com/post/ai-agent-hype-and-reality)
Tool Use
Connect AI to function code, databases, APIs, web search, and other external tools and services for tasks it cannot do directly.
The agent analyzes your request and determines it needs external data or a specific action (e.g., "What is the stock price of Apple?"). It then selects the appropriate tool (e.g., a finance API), generates the correct parameters to call that tool, receives the output, and integrates it into its final response.
The Model Context Protocol (MCP) is currently a critical standard for making tool use more efficient and scalable. Before MCP, developers had to write custom "glue code" for every new tool an agent needed to use. MCP standardizes how agents discover and interact with external data and tools. Connecting N models to M tools requires N X M custom integrations. MCP reduces this to N + M effort, where any model supporting the protocol can immediately use any tool (server) that also supports it. See the MCP service in the SOA architecture of GenAI applications shown above.
GenAI Evaluation (Eval)
Eval is the process of measuring how well a GenAI system performs on the things that matter: correctness, usefulness, safety, grounding, and consistency.
To evaluate the output of a GenAI system, we can create a dataset of prompts and ground-truth answers, similar to how we prepare test cases for software testing. When evaluating a subjective task, such as which chart looks better, we can use an LLM as a judge. However, grading using a rubric or checklist yields more consistent results. We can also use external feedback in evaluation, such as using code, web search, and other tools.
A GenAI system can also critique its own work and iterate to improve quality. This is often referred to as Reflection and Self-Correction. The system evaluates its output, checks for accuracy and gaps (the reflection phase), and improves its work before presenting it, thereby enhancing reliability (the self-correction phase).
Because GenAI output is often probabilistic and non-deterministic, and can include hallucinations, the eval usually combines several methods, such as Human Review, Automated Metrics, Rubric-Based Scoring, LLM-as-Judge, Regression Testing, Red-Teaming, and Adversarial Testing, rather than relying on a single score.
Multi-Agent Collaboration
Multi-agent collaboration in GenAI applications means using several specialized AI agents together rather than a single model or a monolithic agent. Each agent handles a narrower role, and a coordinator or supervisor agent routes tasks, shares context, and merges results into one final outcome.
Multi-agent collaboration is useful when a task is too complex for a single agent to handle well. It can improve goal success, parallelize work, and reduce the load on any single model by allowing each agent to focus on a smaller context window and a specific area of expertise. This distributed approach enhances accuracy, adaptability, and scalability by allowing agents to divide responsibilities and share information. (https://www.kosta-online.com/post/ai-agent-hype-and-reality)

III. Generative AI Agent Patterns
A Generative AI(GenAI) Agent is an autonomous or semi-autonomous software system that uses generative AI models, typically large language models (LLMs), to perceive inputs, reason about goals, plan actions, use tools, and generate outputs to accomplish tasks. Unlike a simple chatbot, a generative AI agent can decide what steps to take and execute them.
AI coding agents are a kind of generative AI agent, which is, in turn, a kind of AI agent. The following are GenAI agent patterns that AI coding agents should inherit.
Foundation Model Wrapper
Generative AI agents use foundation models as the inferencing engine. While foundation models (like Claude Opus and Sonnet) are passive generators of text or images, AI agents (like Claude Code) wrap these models with additional components — such as planning, memory, and tool-use capabilities — to make them autonomous actors that can execute multi-step tasks.
Several AI agent coding patterns (explained below) support this AI agent pattern: Context Engineering, Environment Configuration, Persistent Memory, State Management, Agent Teams, and Parallel Subagents.

Agentic Workflow
An agentic workflow, promoted by Andrew Ng, is a multi-step reasoning loop in which a generative AI agent plans, executes actions, evaluates results, and refines or retries actions as needed, rather than issuing a single prompt for a single answer. (https://learn.deeplearning.ai/courses/agentic-ai/information)
Several AI agent coding patterns (explained below) support this AI agent pattern: Agentic Engineering Workflow, Ralph Loop, Iterative Human-in-the-Loop, and Incremental Development.

Harness Engineering
The term is defined by the formula Agent = Model + Harness. While GenAI focuses on the "raw intelligence" (the model), agentic AI requires a harness to provide the execution layer. Harness engineering builds the orchestration logic, memory infrastructure, constraints, feedback loops, and sandboxed environments that wrap around an AI model to make it a reliable "work engine".
Intent-Driven Development (IDD)
IDD is the pattern where you start from intent — the outcome, goal, or constraint — and let an AI agent decompose it into actions, plan the work, and carry out the implementation. In practice, it means humans specify what they want, while the agent figures out how to get there through planning, tool use, and iteration.
An IDD workflow usually has three parts: Intent capture defines the goal, boundaries, and success criteria. Intent decomposition breaks the goal into subtasks, dependencies, and checks. Agent execution lets one or more agents implement, verify, and refine the result.
Several AI agent coding patterns (explained below) support this AI agent pattern: Macro Prompts, Specification-Driven Development (SDD), Image as Spec (Show than Tell), and Explore-Plan-Code.
Planning and Task Decomposition
Break complex tasks into executable steps that AI can follow and adapt when things don’t go as expected. A high-level task is decomposed into multiple lower-level tasks called Actions, each of which can be implemented using either an LLM or a tool. This is essentially identical to process decomposition in BPM, in which the lowest-level activities called (atomic) tasks are mapped to use cases. Actions in agentic workflows can be executed in parallel or along a decision tree, just like tasks in BPMN business process models.
The Explore-Plan-Code pattern of AI agent coding (explained below) supports this AI agent pattern.

Plan as Code
A plan for an agent workflow can be generated in a programming language such as Python rather than in natural language or the JSON data format. It offers several advantages: Code enforces a higher level of logical rigor; It enables agents to handle tasks requiring math, data manipulation, or "for loops" that are difficult to manage in a standard chat window; Using raw Python to build these workflows allows developers to see exactly how each step works without it being hidden inside a complex framework. (https://learn.deeplearning.ai/courses/agentic-ai/information) The Explore-Plan-Code pattern of AI agent coding (explained below) supports this AI agent pattern.
ReAct
Execute the reasoning-acting loop step-wise. In each loop, ask the agent to produce a structured execution plan, then review the plan and approve it for execution. This pattern enforces deterministic tool invocation, reduces cascading hallucination, and clarifies dependency ordering.
Explore-Plan-Code and Role Switching are AI agent coding patterns (explained below) supporting this AI agent pattern.

Eval-Driven Development (EDD)
EDD means using evaluations as the specification and control loop for an AI agent. Instead of treating evals as an afterthought, you first define what “good” looks like, encode it into tests or rubrics, and then use those results to guide prompt changes, tool choices, model swaps, or workflow redesign.
Core ideas are: Eval first, meaning write the checks before or alongside the agent behavior; Build to the eval, meaning iterate until the agent passes the checks reliably; Keep evaluating, meaning run the same evals continuously so regressions are caught early.
Several AI agent coding patterns (explained below) support this AI agent pattern: Constraint-Driven Coding, Refactor-As-Transformation, Deterministic Output Contracts, and Self-Verification.
Component-Level Evals
There are two types of evaluations: end-to-end evals and component-level evals. Component-level evals can avoid the noise in the end-to-end system and provide a clearer signal for specific errors. They work on smaller, more targeted problems faster, allowing the team to be more efficient.
We can examine traces to perform error analysis. We can conduct error analysis to determine which component performed poorly, resulting in poor final output. Use error analysis output to decide where to focus efforts. (https://learn.deeplearning.ai/courses/agentic-ai/information)
Self-Verification and Error-Driven Refinement are AI agent coding patterns (explained below) that support this AI agent pattern.
AI Agent Loop
AI agent loops are the foundational, iterative process that enables autonomous AI agents to perform complex, multi-step tasks by breaking them down into manageable cycles of reasoning, acting, and evaluating. Unlike traditional “one-shot” AI prompts, an agent loop runs continuously — often in a while loop — to refine work, use external tools, and handle unexpected, dynamic environments until a final goal is met.
Several AI agent coding patterns (explained below) support this AI agent pattern: Ralph Loop, Explore-Plan-Code, Context Window Optimization, Bounded Context Injection, Role Switching, Iterative Human-in-the-Loop, Persistent Memory, State Management, Reusable Saved Prompts, Incremental Development, Autonomous Version Control, Best of N, and Analytics and Monitoring.

Service-Oriented Agent Architecture
GenAI agents themselves are internally SOA and interact with external systems via SOA APIs. (https://www.kosta-online.com/post/ai-first-and-api-first-strategies; https://www.kosta-online.com/post/ai-agent-system-is-soa; https://www.kosta-online.com/post/ai-agent-hype-and-reality)
The inner SOA architecture of a GenAI agent composes SOA services either through orchestration via a BPMS or through choreography via a pub/sub event bus, as shown in the GenAI Agent Architecture diagram above. The diagram below shows GenAI agent orchestration using the Camunda BPM platform.
Bounded Context Injection and API Integration are AI agent coding patterns (explained below) that support this AI agent pattern.

Ontology Engineering
Ontology engineering is increasingly becoming a core architectural pattern for enterprise-grade GenAI agents, particularly in complex business, industrial, and regulated environments. It uses structured semantic models—such as ontologies, knowledge graphs, taxonomies, and policy metadata—to define the meaning, relationships, constraints, and operational context of business data.
Instead of relying solely on prompts or raw databases, the agent can use an ontology as the semantic layer to interpret context accurately, reduce hallucinations, select the correct tools, follow governance rules, and coordinate across systems.
Various tools can be used to build an ontology: ontology modeling tools such as Protégé, knowledge graph platforms such as Palantir Ontology/Foundry and Neo4j, metadata and data catalog tools such as Informatica and Alation, UML and ER modeling tools such as Visual Paradigm and Sparx Enterprise Architect, or Vector DBs such as Pinecone.
Context Management
Context perception and state management are foundational components of GenAI agents, enabling them to be autonomous, context-aware systems. See this component as an SOA service within the Generative AI Agent Architecture above. (https://www.kosta-online.com/post/ai-agent-hype-and-reality)
While perception allows the agent to interpret its environment and gather data, state management ensures continuity by maintaining a record of past actions, decisions, and environmental changes, enabling the agent to operate effectively over long-term, multi-turn interactions.
In AI agent loops, each iteration resets the in-context state but relies on external state for continuity, which is the architectural workaround for the context window limitation.
Several AI agent coding patterns (explained below) support this AI agent pattern: Context Engineering, Context Window Optimization, Environment Configuration, Persistent Memory, and State Management.
Long-Term Memory
An agent's long-term memory is broader and more operational than that of a general GenAI application. It stores past actions, tool results, task state, decisions, failures, and learned strategies so the agent can continue a workflow or choose better actions in the future.
Agent memory often includes episodic memory, which stores what happened in previous interactions or tasks; semantic memory, which stores facts, rules, and knowledge; and procedural memory, which stores how to do things, such as preferred workflows or tool sequences. It is critical to develop a centralized set of validated services (such as LLM observability or preapproved prompts) and assets (for example, application patterns, reusable code, and training materials) that are easy to locate and use, and to integrate these capabilities into a single platform. (https://www.mckinsey.com/capabilities/quantumblack/our-insights/one-year-of-agentic-ai-six-lessons-from-the-people-doing-the-work#/)
In agent coding, developers can store shareable artifacts such as project guidelines, best practices, reusable prompts, and example code in long-term memory, such as Claude.md, Skills, and Knowledge Repository. Several AI agent coding patterns (explained below) support this AI agent pattern: Project Structure, Context Window Optimization, Environment Configuration, Memory Snapshot, Persistent Memory, Repeatable Commands, State Management, and Reusable Saved Prompts.
Agentic RAG (Retrieval-Augmented Generation)
Agentic RAG (a.k.a. RAG 2.0, agentic retrieval) is an advanced evolution of RAG, where an AI agent autonomously plans and manages the search process rather than following a fixed, one-time retrieval step. Unlike traditional RAG—which simply takes a user query, finds similar documents, and generates an answer—agentic retrieval turns the process into a dynamic reasoning loop.
An agentic system can perform query decomposition, dynamic source selection (routing), multi-source reasoning, and self-correction, reducing hallucination, handling more complex questions, and adapting its search strategy on the fly.
Agentic Multi‑Agent Collaboration
In agentic AI, multi-agent collaboration is usually about autonomous coordination: agents have roles, pass tasks, manage state, and often work through a supervisor or hierarchy to complete multi-step goals. The collaboration is tied to goal completion over time. Agents plan, act, hand off, verify, and continue until the objective is done.
Agent Teams and Parallel Subagents are AI agent coding patterns (explained below) that support this AI agent pattern.
Autonomous Closed-Loop Feedback
The agent can verify its performance at each step of the workflow. Building a monitoring-evaluation-learning closed-loop feedback into the workflow can enable teams to catch mistakes early, refine the logic, and continually improve performance. (https://www.mckinsey.com/capabilities/quantumblack/our-insights/one-year-of-agentic-ai-six-lessons-from-the-people-doing-the-work#/; https://www.kosta-online.com/post/ai-agent-hype-and-reality)
In agent coding, the software development workflow may include multiple checkpoints where the agent autonomously verifies intermediate results against pre-specified rules. Unlike other types of AI agents, AI coding agents don’t have a native, autonomous Learning Closed-Loop Feedback facility. Iterative Human-in-the-Loop and Analytics & Monitoring are AI agent coding patterns (explained below) that support this AI agent pattern.
Cost Optimization
You can measure LLM steps (pay per token), any API-calling tools (pay per API call), and compute steps (based on server capacity/cost) spent in your agent workflow. You may consider parallelism and try a smaller, less intelligent model, or a faster LLM provider.
Performance Optimization and Analytics & Monitoring are AI agent coding patterns (explained below) that support this AI agent pattern.

Human-in-the-Loop
A loss in trust or a decline in quality can easily offset any efficiency gains achieved through automation. Developers should give agents clear job descriptions, onboard them, and provide ongoing feedback so they become more effective and improve over time. Developing effective agents is challenging work that requires harnessing individual expertise to create evaluations and codifying best practices with sufficient granularity for given tasks. This codification serves as both the training manual and performance test for the agent, ensuring that it performs as expected. (https://www.mckinsey.com/capabilities/quantumblack/our-insights/one-year-of-agentic-ai-six-lessons-from-the-people-doing-the-work#/; https://www.kosta-online.com/post/ai-agent-hype-and-reality)
Agent coding cannot produce production-grade applications without human guidance and interventions. The AI agent coding patterns supporting this AI agent pattern are Iterative Human-in-the-Loop, Two-Way Communication, Community Contributions, and Best of N, as explained below.

IV. Software Engineering Patterns
It is important to apply software engineering patterns when developing high-quality software using an agent coding platform. Important software engineering patterns include UX design patterns, behavior-driven design (BDD) patterns, SOLID patterns, Gang of Four object design patterns, domain-driven design (DDD) patterns, refactoring patterns, clean code patterns, service-oriented architecture (SOA) patterns, test-driven design (TDD) patterns, and so on.
Executable Process Model
A conceptual-level business process model designed for digital transformation should be transformed into an executable-level process model that can be implemented by a BPMS (Business Process Management Suite)-based orchestration, or a pub/sub event bus-based choreography in a service-oriented architecture (SOA). (https://www.kosta-online.com/challenge-page/bpmn-based-business-process-design-and-implementation)
Several AI agent coding patterns (explained below) support this SE pattern: Agentic Workflow, Agentic Engineering Workflow, Context Perception and State Management, Policy and Guardrails, Context Engineering, Role Switching, and Agent Teams.
Requirement Specification
The software's behavior (functionalities, features, use cases) and structure (semantics, business objects, data) should be specified. The business analyst can specify the behavior using BPMN-based business process models, use cases, BDD acceptance criteria, use case scenarios, etc., and the structure using a UML conceptual-level class diagram, entity-relationship diagram, ontology, etc. (https://www.kosta-online.com/post/the-complete-guide-to-business-analysis)
As in Design Thinking, the Lean Startup, and Agile Development, the software should be built incrementally, ensuring that the features added at each increment are well received by users.
The level of specification rigor should be calibrated to the increment size and risk: BPMN + UML + BDD for high-risk, core domain logic; use cases + BDD acceptance criteria for medium-complexity features; and brief story + acceptance criteria for low-risk boilerplate/scaffolding. (https://www.kosta-online.com/post/agent-coding-gold-standard)
Several AI agent coding patterns (explained below) support this SE pattern: Macro Prompts, Specification-Driven Development (SDD), Image as Spec, Explore-Plan-Code, Role Switching, Learn by Example, Agent Teams, Parallel Features Development, Feature Flagging, and Best of N.

User-Centric Design
Build interfaces that are intuitive and user-friendly. Conduct usability tests to gather feedback and make improvements. Ensure the app is accessible to all users, including those with disabilities.
Agents are strong UI implementers but weak UI designers — reinforcing the Design Thinking principle that human empathy and user research must precede and govern agent implementation. This pattern is most valuable when explicitly integrated into the Requirement Specification and Agile Development Process rather than treated as a standalone principle.
Several AI agent coding patterns (explained below) support this SE pattern: Image as Spec, Explore-Plan-Code, and Learn by Example.
Use Case Analysis
Functionalities required for an application can be defined as use cases (or user stories in a compact statement). Activities at the leaf level of a business process model decomposition can be mapped to a use case. A use case can be detailed using Use Case Scenarios. (https://www.kosta-online.com/challenge-page/use-case-analysis-and-realization) Each scenario is testable and can be mapped to a Behavior-Driven Development (BDD) scenario. Use cases are realized through Class Responsibility Assignment into domain models (see the Object Design and Domain-Driven Design pattern below)
Several AI agent coding patterns (explained below) support this pattern: Specification-Driven Development (SDD), Explore-Plan-Code, and Agentic Domain Modeling.
Rules Management
Decisions can be implemented by decoupling business logic from application code, allowing non-technical stakeholders to update rules in a searchable library without requiring a full software development lifecycle.
Rules can be specified as a decision table, a decision tree, or a logic diagram in the Decision Model and Notation (DMN) language. Rules are stored in a central Rule Repository, and executed by the Rule Engine, typically using the Rete algorithm.
The Decision Tree pattern (explained below) is the AI agent coding pattern supporting this SE pattern.
Behavior-Driven Development (BDD)
Acceptance criteria in Gherkin syntax are one of the most effective structured prompts for Spec-Driven Development (SDD) in agent coding. Gherkin specifications can serve as a living semantic model — simultaneously a business document, a technical specification, and an executable test suite. The outside-in approach aligns with use-case → domain-model derivation. Acceptance tests double as PRD story-completion verification, and business stakeholders can validate test specifications before agent implementation.
Several AI agent coding patterns (explained below) support this pattern: Specification-Driven Development (SDD), Explore-Plan-Code, Self-Verification, and Agentic Domain Modeling.
Object Design and Domain-Driven Design (DDD)
A domain model should be developed from the semantic model and use cases for the application built with agent coding. (https://www.kosta-online.com/post/the-complete-guide-to-business-analysis) Domain-Driven Design (DDD) is a widely used software development method based on domain models. (E. Evans, Domain-Driven Design: Tackling Complexity in the Heart of Software, 2003.)
The Class Responsibility Assignment method (often using Class-Responsibility-Collaboration (CRC) cards) can be used to design the domain model, which maps tasks in use case scenarios to methods in conceptual-level classes in the semantic model or methods in design-level classes. The GRASP Pattern can be applied in the Class Responsibility Assignment. (C. Larman, Applying UML and Patterns: An Introduction to Object-Oriented Analysis and Design and the Unified Process, 2001.)
Object design principles, such as SOLID, object design patterns, such as Gang of Four Patterns, and Refactoring Patterns should be applied to the domain model and the resultant code. (https://www.kosta-online.com/challenge-page/object-design)
An agent coding session should focus on a bounded context in the domain model so that the entire codebase does not overload the context window. The application developed via agent coding should be built on a service-oriented architecture, where each service corresponds to a bounded context. Each service can be implemented using the Hexagonal Architecture. (https://www.kosta-online.com/post/the-complete-guide-to-soa-msa-and-modulith)
Several AI agent coding patterns (explained below) support this SE pattern: Policy and Guardrails, ReAct, Explore-Plan-Code, Agentic Domain Modeling, Bounded Context Injection, Constraint-Driven Coding, and Refactor-As-Transformation.

SOA
Break down the application into smaller, manageable services to enhance functional cohesion, loose coupling, implementation-agnostic design, maintainability, reusability, and ease of testing and debugging. Use well-defined APIs to interact with other services and external systems. Maintain clear documentation for API endpoints. Use API versioning to manage changes and updates without breaking existing functionality.
Choose from SOAP-based SOA, Microservice Architecture (MSA), and Modular Monolith (Modulith) Architecture styles and patterns, depending on which architecturally significant requirements (ASRs) (e.g., maintainability, data consistency, reusability, operational simplicity, agility, scalability) are most important. (https://www.kosta-online.com/post/the-complete-guide-to-soa-msa-and-modulith; https://www.kosta-online.com/challenge-page/deep-understanding-of-microservice-architecture)
Modulith architecture is often relevant for applications built using agent coding. Compared with MSA, it allows simpler deployment, lower DevOps overhead, an easier path to refactoring as the domain model evolves, and lower operational complexity, allowing teams to focus on agent coding quality. When a bounded context within the application requires a microservices architecture, you can apply the Strangler Fig pattern to migrate only that part from Modulith to MSA. (https://learn.microsoft.com/en-us/azure/architecture/patterns/strangler-fig)

Several AI agent coding patterns (explained below) support this SE pattern: Agent in SOA, Agentic Domain Modeling, Bounded Context Injection, and API Integration.
Test-Driven Development (TDD)
Run the test(red)-code(green)-refactor loops. TDD can produce a well-structured test pyramid. (https://www.kosta-online.com/challenge-page/tdd-based-test-automation) Agents can write tests before implementation to force clearer thinking and fewer hallucinations. TDD emerges as one of the strongest patterns for succinct, reliable code from coding agents.

However, when you ask an LLM to "write a feature," it tends to work in horizontal slices — it writes the entire feature first, then writes tests for that feature afterward. Tests written in bulk test imagined behavior, not observed behavior. When the LLM generates 10 tests up front and then implements them to pass them all, several bad things can happen — including rewriting the test to make it pass when context runs low, instead of writing a real implementation.
The solution is structural enforcement — making TDD the path of least resistance through architecture, not willpower. For example, with Claude Code, a complete stack for TDD can be as follows:
CLAUDE.md: Mandatory rules for Tests-First policy loaded every session
PostToolUse Hook: Auto-runs tests after every file edit, giving an immediate feedback loop
TDD Skill: Procedural memory for Red-Green-Refactoring cycle in the planning phase
RED Subagent: Isolated context, write-test-only
GREEN Subagent: Isolated context, minimal-code-only
REFACTOR Subagent: Isolated context, no-new-behavior, but quality without feature creep
Pre-commit Hook: Blocks commit below coverage threshold as a TDD gate at the version control level
Explicit Prompting: Phase-specific, human-enforced prompt per step
Asking an LLM to "do TDD" without structural enforcement is like asking water to flow uphill. TDD operates on the same principle as security governance — constrain behavior through architecture. Instead of hoping the agent writes good code, make good code the only path forward.
TDD saves tokens long-term. Without TDD: prompt generates 500 lines of code → bug found → agent reads error logs (2,000 tokens) → modifies code → new bug → reads more context (3,000 tokens) → total: 50,000+ tokens. With TDD: write minimal test (200 tokens) → test fails (expected) → write minimal code → test passes → total: 5,000 tokens. The TDD workflow has a higher upfront token tax but dramatically lower total cost over a feature's lifetime.
Several AI agent coding patterns (explained below) support this SE pattern: Specification-Driven Development, Refactor-As-Transformation, and Error-Driven Refinement.
Static Analysis
There should be quality gates at which the agent performs linting, type checking, and security scanning on its own output before submitting.
Several AI agent coding patterns (explained below) support this SE pattern: Reflection and Self-Correction, Constraint-Driven Coding, Error-Driven Refinement, and Self-Verification.
Continuous Integration (CI)
CI (Continuous Integration) is the practice of frequently merging code changes into a shared branch and automatically building, testing, and validating them so problems are detected early. In agentic coding, CI is the main mechanism that enforces quality and correctness on AI-generated code before it is merged or deployed.
A CI pipeline automatically builds the project, runs unit/integration tests, runs linters, type checks, and security scans, and reports pass/fail status. If CI fails, the change is not merged or not shipped. The CI pipeline can automatically feed the stack trace back to the agent. This allows the agent to self-correct its hallucination in a closed-loop system without human intervention.
CI in agentic coding is the automated quality gate that agents must pass before their changes are integrated, and in “agentic CI,” the pipeline itself uses AI agents to review, fix, and improve code automatically.
Agentic CI uses CI/CD platforms such as GitHub Actions, Buildkite, and CircleCI that run pipelines and host agents, as well as AI/agent tooling and protocols that run inside the pipeline as steps.
As in the TDD pattern above, context files, hooks, skills, and subagents can complement traditional CI, catching violations earlier and reducing CI failures.
Documentation and Training
Maintain thorough documentation for both developers and users. Use comments in your code to explain complex logic. Create user-friendly guides to help users navigate the application.
Agent coding amplifies the importance of documentation in three ways: AGENTS.md / CLAUDE.md as living documentation, code comments as agent context, and agent-generated documentation such as API docs, code comments, and user guides.
Several AI agent coding patterns (explained below) support this SE pattern: Persistent Memory, Repeatable Commands, and Community Contributions.
Agile Development Process
Develop software iteratively and incrementally in AI agent coding, ensuring each increment is viable through thorough testing and user review. (https://www.kosta-online.com/challenge-page/cloud-native-computing-adoption-roadmap)
An XP (Extreme Programming)-based Scrum or Kanban development process within a Lean Startup loop, followed by a Design Thinking loop, is widely used. An extended agile process, such as the Scaled Agile Framework (SAFe), can be used for a large project to implement within an Enterprise Architecture framework.
DevOps, based on XP and CD (Continuous Delivery), is an appropriate development process for a very large project with many decentralized teams that requires extreme agility and independent scaling across services. DevOps enables continuous delivery based on a microservices architecture (MSA), allowing each service to be deployed independently. In agent coding, DevOps (with SAFe providing a cross-team coordination layer) can be chosen when MSA is chosen as the SOA style.
Several AI agent coding patterns (explained below) support this SE pattern: Incremental Development, Autonomous Version Control, Parallel Features Development, Feature Flagging, and Best of N.

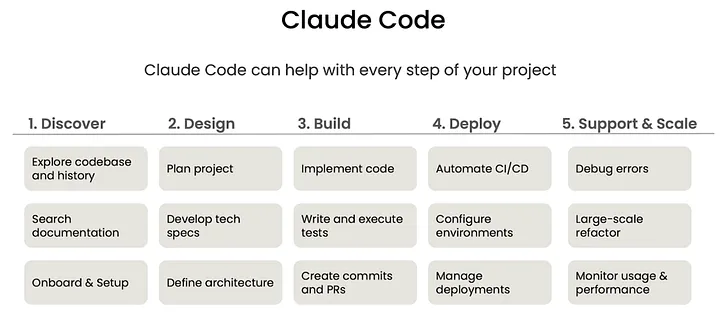
V. AI Coding Agent Patterns
When developers use coding agents (with a large language model, tools, file systems, a terminal, and a planning loop), effectiveness depends less on prompt tricks and more on architectural interaction patterns among the human, the agent, and the codebase. Below are high-leverage agent coding patterns, framed for production app development rather than toy examples.

Macro Prompts
The very first, simplest, most important step in agent coding is to step back from tiny, micromanaging prompts that keep us tightly in the loop on every single change. We should step back and start thinking of ourselves as innovators and entrepreneurs with big ideas that leverage AI labor, scale it up, and use it in scalable ways that deliver a thousandfold improvement in software engineering productivity. (https://www.coursera.org/learn/claude-code/lecture/zEjfi/1000x-improvement-in-software-engineering-productivity-with-big-prompts)
Specification-Driven Development (SDD)
Treat the prompt not as prose but as a formal specification artifact. Specify, for example, a Product Requirements Document (PRD) written in Markdown, use cases for business flow, a semantic model for domain entities and invariants, and acceptance criteria in Gherkin style for executable constraints. That reduces reasoning entropy, enables deterministic planning, and converts a creative LLM into a constrained planner. (https://www.thoughtworks.com/radar/techniques/spec-driven-development)
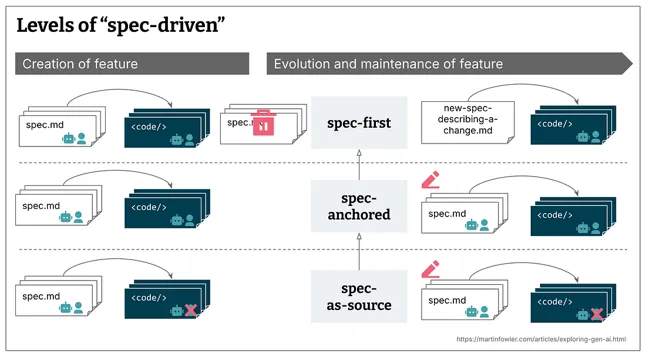
AI coding agent platforms (like Claude Code, Cursor, Windsurf) produce superior, production-ready code when guided by more rigorous, structured requirement specs. By specifying precise, machine-readable specifications — e.g., a UML semantic model, BDD Gherkin-style acceptance criteria, use cases in TypeScript, and API contracts in OpenAPI — agents can generate complex, multi-file components, significantly reducing technical debt and improving reliability.
Image as Spec (Show than Tell)
When working with Claude Code, certain concepts are dramatically easier to communicate through images than through text descriptions: colorful UI wireframe design, screenshots, example documents, data visualization charts, dashboard mockup, business process model diagram, decision tree, UML class diagram, entity relationship diagram, architecture diagram, video or animated GIF, performance data graph, network topology diagram, etc.
You can submit UML and BPMN models as an image prompt for backend development. It can, however, enhance accuracy and round-trip engineering if you convert those diagrams to text using Diagram-to-Code tools such as PlantUML and Mermaid.

Spec-to-Scaffold Automation
Let the agent generate the project structure, set up the Docker file, and configure CI. Then freeze the structure before business logic begins.
Project Structure
The project structure, naming, and directory structure are really important contexts for Claude Code to locate the code to change. Applying de facto standards for naming conventions, layouts, frameworks, and libraries makes it easier (i.e., token-efficient) to figure out where things are and what they do from the names alone.
Agentic Software Engineering Workflow
Agentic Engineering Workflow is a structured development process for building AI agent systems, where large language models (LLMs) act as agents that plan, reason, use tools, collaborate, and iterate to complete software development tasks. This pattern extends the agentic workflow pattern of gen AI agents, but focuses specifically on how software engineers analyze, design, build, test, and deploy agent-based applications.
Iterative Agentic Coding Loop (Ralph Loop)
Ralph Loop implements the Agentic Engineering Workflow using a bash-based orchestration loop that wraps an AI coding tool and runs it repeatedly and autonomously until all requirements spec items are complete. The agent restarts with fresh context for each iteration to prevent context degradation and corruption, using Git and file systems as persistent external memory to maintain continuity across iterations.

Explore-Plan-Code
Separate research and planning from implementation to avoid solving the wrong problem. Spend more time designing and innovating.
Rapidly prototype with personas to explore requirements and options. Do rigorous requirement modeling, such as UML semantic modeling, BPMN business process modeling, and use case modeling to specify requirements with a maximum of 4C’s (correctness, consistency, completeness, and comprehensibility).
Then craft constraints and prompts. Let Claude Code generate code and then commit with a descriptive message and create a PR. (https://code.claude.com/docs/en/best-practices)
Context Engineering
Curating what the model sees to improve results. Claude Code can infer intent, but it can't read your mind. Reference specific files, mention constraints, and point to example patterns. Claude Code's context configuration features include Claude.md, Rules, Skills, MCP servers, Subagents, Hooks, Plugins, and Slash commands.

You can provide rich data to Claude in several ways: Reference files with @; Copy and paste images directly into the prompt; Give URLs for documentation and API references; Use /permissions to manage tool allowlists; Pipe in data by running cat error.log | claude to send file contents directly; Tell Claude to pull context itself using Bash commands, MCP tools, or by reading files.
Context Window Optimization
Manage the Context Window so that it does not feed the whole repo, but only the directory map, relevant files, and architectural constraints. During long sessions, the context window can fill with irrelevant conversation, file contents, and commands, reducing performance and sometimes distracting Claude. Use /clear between tasks to reset the context window. Use /compact to preserve key decisions while freeing space.
Agentic Domain Modeling
Agent coding platforms like Claude Code design workflows, classes, and SOA services based on requirement models, such as BPMN process models, UML semantic models, use case scenarios, and BDD acceptance criteria. (https://www.kosta-online.com/post/agent-coding-gold-standard)
The agent coding platform first classifies verbs (i.e., activities and tasks) in behavioral models into process activities (more abstract activities) and class operations (unit tasks). It then connects process activities into a workflow, while assigning class operations to conceptual-level classes and design-level classes as their methods. (https://www.kosta-online.com/post/agent-coding-gold-standard)
The latter assignment method is called Class Responsibility Assignment, often using Class-Responsibility-Collaboration (CRC) cards, and applying the GRASP method. (C. Larman, Applying UML and Patterns, 2001) Class Responsibility Assignment produces the domain model and CRC cards for the application being built, which you can ask Claude Code to present to you for review, correction, and approval. (https://www.kosta-online.com/post/agent-coding-gold-standard)
API Integration
Both the inner and outer architecture of agent coding platforms like Claude Code are SOA. So, you can use Claude Code’s API to send requests and receive responses, providing a clear, structured way to interact with the AI coding agent. There are several ways the agent integrates with systems via APIs: direct API calls, tool invocation, the MCP (Model Context Protocol) gateway, the A2A (Agent-to-Agent) protocol, and unified API platforms.

The application built using an agent coding platform should also be in SOA. The agent maps bounded contexts in the domain model to SOA services, producing a Context Map in DDD. The workflow designed by the agent using process activities is used to compose SOA services into an application. The agent implements service composition via centralized orchestration using a BPMS or via decentralized choreography using a pub/sub event bus, depending on the application's architecturally significant quality attributes. (https://www.kosta-online.com/post/the-complete-guide-to-soa-msa-and-modulith)
The agent generates the service APIs, test code, and source code based on behavioral requirement specifications, the domain model, and the SOA architecture design.
Bounded Context Injection
To avoid a large codebase overloading the context window, focus on a single bounded context in the domain model per session. To optimize the context window, it is important to design software that is modular within a service-oriented architecture.
Environment Configuration
Write an effective CLAUDE.md. Configure permissions. Configure CLI flags and environment variables. Install plugins. Connect the MCP servers. Set up hooks. Create skills. Create custom subagents. Configure Agent Teams. (https://code.claude.com/docs/en/best-practices)
Constraint-Driven Coding
The agent uses TDD to ensure that the generated code satisfies the requirements. You may embed explicit constraints, such as “Perform unit testing for every basis path in each class” and “No ORM, use raw SQL.” Agents optimize strongly around explicit constraints.
Refactor as Transformation
The agent performs far better with measurable transformation goals: for example, "Reduce cyclomatic complexity to less than 10" and "Conform to SOLID principles."
Role Switching
Have the agent switch roles sequentially: for example, "Act as an architect, a security reviewer, a performance engineer, and then a QA." This pattern creates structured critique loops without changing context.
Memory Snapshot
Before a large change, take a snapshot of memory: for example, "Summarize the current architecture in 10 bullet points."
Deterministic Output Contracts
Require strict formats to prevent narrative drift and allow programmatic parsing. For example, "Return JSON with files modified, migrations, and new dependencies."
Error-Driven Refinement
When a test fails, let the agent explain the root cause, propose a fix, and show the patch only (i.e., do not allow a full rewrite).
Diff Edit
Require the agent to "output unified diff only" and "not rewrite unchanged code." Otherwise, the agent rewrites entire files. Benefits of diff edit include safe incremental edits, Git-friendly, and easier review. Claude-like coding agents respond well when constrained to patch semantics.
Iterative Human-in-the-Loop (HITL)
Even highly autonomous systems benefit from structured human oversight. Humans should approve risky changes and review architectural decisions. These ensure accountability and prevent the silent accumulation of technical debt. (https://www.kosta-online.com/post/vibe-coding-benefits-and-limitations) In Claude Code, use Plan mode, Diff review, Permission prompts, and /rewind for HITL iterative review.
Google requires human code review for every code change by at least one person (e.g., a readability specialist, the code owner, or a peer developer), even if Google developers use its own agent coding platform, the Gemini Code Assist, as an intelligent coding partner. (https://www.michaelagreiler.com/code-reviews-at-google/)

When Andrej Karpathy, a founding researcher at OpenAI and former director of AI at Tesla, was asked if a few prompters would replace large development teams, he explicitly pushed back, arguing that "top-tier, deep technical expertise may be even more of a multiplier than before." (https://www.implicator.ai/karpathy-says-ai-coding-agents-made-programming-unrecognizable-since-december/)
Two-Way HITL
Agents proactively ask humans questions when uncertainty arises during instruction execution, preventing unsafe actions or hallucinations. On the contrary, you can ask the agent questions as you would ask another engineer, especially when you are onboarding to a new codebase. For larger features, have the agent interview you using the AskUserQuestion tool. Ask the agent to correct as soon as you notice it going off track. For example, you can copy and paste an error message from running the agent-generated app into the prompt to ask the agent to fix the error.
Self-Verification
Provide Claude Code tests, screenshots, or expected outputs so Claude can check its own work. For example, write the following in Claude.md so it loops: "When you build new code, write tests for it (including unit, integration, and user acceptance tests), and before you check in, go and compile the code and make sure it passes all the tests."
Learn by Example
Provide Claude Code example code to learn core design, style, conventions, and principles.
Persistent Memory
Claude.md is the project team's persistent memory — essential context that provides the institutional global knowledge and is available in every prompt. It should include clear, concise instructions; operational processes; naming and standards; testing and quality gates; examples and references; expectations and boundaries; and tools and dependencies.
You can also ask Claude to first write codebase research in research.md, which you review and correct before any planning begins. Then ask Claude to save its implementation plan as FEATURE_PLAN.md or INTEGRATION_DESIGN.md. Annotate the plan file directly and ask Claude to update it. Repeat this annotation loop several times until the plan fits your system precisely.

RAG is also a persistent memory managed by coding agents such as Claude Code. Once the agent exceeds the context window limit, it automatically switches to RAG mode, indexing your documents and retrieving snippets as needed. You don't have to manage the database or the embeddings yourself; it’s a fully managed service.
Repeatable Commands
Claude Code commands (slash commands) deliver targeted context and process for specific, repeatable tasks — think of them as specialized instruction sets that give Claude Code exactly what it needs for particular workflows without overwhelming it with irrelevant information.
Commands are stored as Markdown files in .claude/commands/ and ~/.claude/commands/. Command files support YAML frontmatter (allowed-tools, model, description, argument-hint), dynamic bash execution (!), file references (@), and $ARGUMENTS for parameterization. MCP servers can also expose prompts that automatically become slash commands.
Community Contributions
If you contribute to a community, a Claude.md file, Claude Code commands, innovative process documentation, and creative solutions to common development challenges, that will help other developers skip the trial-and-error phase and jump straight to productive AI-assisted Development. Every shared command becomes a building block for the next developer's breakthrough.
State Management in Agentic Coding
Keep track of conversation state and application context within a session by leveraging Claude’s ability to maintain context across multi-turn exchanges in the active context window. This pattern improves user experience in ongoing conversations by allowing Claude to dynamically adjust responses based on previous interactions — useful for context-aware replies and iterative refinement.
To maintain context between sessions, write persistent instructions and project conventions to CLAUDE.md; rely on Auto Memory and Session Memory, which automatically extract and save structured summaries of past sessions; explicitly save written artifacts like research.md or PLAN.md for Claude to reference in future sessions; or resume a specific past session directly.

Reusable Saved Prompts
Turn repeated instructions into persistent components. Put short, always-applicable rules, such as naming conventions and architecture standards, into CLAUDE.md; Put complex, procedural, or domain-specific workflows like testing procedures or deployment steps into Skills; and use slash commands for explicit, user-initiated repeatable actions.
Agent Teams in Agentic Coding
Let a Manager Agent coordinate a Frontend Agent (React components, UI state), a Backend Agent (API routes, server logic), and an Infrastructure Agent (schema, migrations, deployments) — all running in parallel, communicating with each other. Frontend Agent and Backend Agent need to keep an API contract in sync while building simultaneously.

Parallel Subagents in Agentic Coding
Let a Product Agent create requirements and specs, a UX/Design Agent design UI flows and wireframes, and Claude Code as the Coding Agent implement the result, with humans serving as the supervisor of the three subagents and the quality gate between each phase. Let a Planner Agent break a big task into tiny, ordered steps and let an Executor Agent (Claude Code) receive and implement each task independently. Let a Reviewer Agent critique and improve another agent’s output before it reaches a human. Each subagent has a single responsibility, with scoped tool permissions.
Decision Tree
If-Then-Else decisions can be implemented in many different ways in agent coding: as a prompt (e.g., agent instruction in BDD acceptance criteria, policy in the system prompt), in code (using Match-Case or GoF Strategy pattern), or as a workflow-level logic.
When the decision is made at the workflow level, it can be implemented as a (decision) node in the workflow using a BPMS like Camunda, as a graph-based workflow (i.e., State Machine) using an agent framework like LangGraph, using an LLM-based decision router, by calling a MCP tool such as Business Rule Management System (BRMS), or by delegating to a specialized decision agent.
Non-Interactive Mode
You can run Claude non-interactively without a session. Claude Code scales horizontally with parallel non-interactive batch operations. Non-interactive mode is how you integrate Claude into CI pipelines, pre-commit hooks, or any automated workflow. You can distribute work across many parallel batch operations.
Autonomous Mode
You can have Claude Code bypass all permission checks and work fully unattended. This pattern works well for well-scoped, non-critical workflows like fixing lint errors or generating boilerplate, but only with mandatory safety prerequisites in place: e.g., always git commit before creating a rollback point; scope tasks tightly with a precise prompt; and set max-turns to prevent infinite loops.
Incremental Development
Implement features in small, verified increments rather than attempting to “one-shot” everything in a single session. Slice each feature into increments small enough that each fits comfortably within a fresh context window and does not cause context rot.
Leave structured artifacts between sessions so that context can be aggressively cleared without losing the project roadmap. The current recommended artifacts are: Tasks stored persistently at ~/.claude/tasks/; Git commit as a rollback point and a progress marker; and PLAN.md or SPEC.md to be referenced at the start of each session.
AI-Assisted Version Control
Let Claude Code create and manage feature branches following naming conventions defined in CLAUDE.md. For maximum context isolation, use branch-scoped CLAUDE.md files that automatically swap context when switching branches via a git hook.
Claude Code handles the full Git lifecycle autonomously: reading GitHub issues → creating feature branches → implementing changes → committing with conventional commit messages → pushing branches → creating PRs with auto-generated descriptions → deploying to staging via GitHub Actions → waiting for deploy confirmation before proceeding.
Feature branches may be abandoned (worktree removed, branch discarded) or later merged into main to cherry-pick the best features.

Parallel Features Development
For simultaneous autonomous development across multiple features, use Git Worktrees. Git worktrees combined with Claude Code create a powerful workflow for parallel development. Instead of juggling multiple branches on a single working directory, Git worktrees give each Claude Code instance its own isolated directory, branch, and file state, all sharing the same underlying Git history and remote connections.
Note that parallel is not always faster. Tasks that share files can produce merge conflicts that take longer than sequential development.
Feature Flagging
A Feature Flag gate keeps merged code behind a flag in the live environment, releasing it only after explicit human approval. Feature flags also enable incremental rollout (1% → 5% → 25% → 100%) with automatic rollback if error rates exceed thresholds, providing a safety net for teams. Combined with Git Worktrees, flags allow Claude Code to run parallel feature experiments simultaneously — each behind its own flag — with no branch interfering with production until a human approves the rollout.

For AI-generated code scanned by Claude Code Security, the feature flag serves as the deployment gate after the security multi-stage verification pipeline — holding flagged code until the security team approves patches in the Claude Code Security dashboard. In regulated environments (HIPAA, SOC 2), feature flag gates are mandatory compliance requirements, not optional workflow choices.
Best of N
When you start deploying AI labor to solve problems, don't have it solve the problem once. Have it solve the problem three, five, ten times, and then give you all of them back so that you can go, evaluate, judge, and decide what you like best and why, or how you want to combine them. (https://www.coursera.org/learn/claude-code/lecture/4EVrV/the-best-of-n-pattern-leverage-ai-labor-cost-advantages)
Performance Optimization
Claude Code’s response speed depends on four factors you control — model selection (among Haiku, Sonnet, and Opus), model routing strategy, context window size, and prompt specificity.
Claude Code automatically enables Prompt Caching, which dramatically reduces input costs.
Use Streaming for real-time partial responses to keep the UI responsive; Message Batches API for bulk async operations; and parallel sessions for independent concurrent tasks — frontend in one session, backend in another.
For application-level optimization, Claude Code identifies and fixes N+1 database query problems, implements connection pooling, adds composite indexes, and suggests Redis caching layers, provided that the developer activates them through deliberate task specification in the PRD or prompt.
Analytics and Monitoring
Three native monitoring layers are available: Console Analytics Dashboard, the Claude Code Analytics API (daily aggregate, organization-wide, low setup effort), and OpenTelemetry integration.
The OpenTelemetry integration exports real-time per-event metrics to any OTel-compatible backend, such as Prometheus/Grafana, Datadog, and ClickHouse. OpenTelemetry is incredibly complex to set up.
The Analytics API provides daily aggregated organization-wide productivity metrics, tool acceptance/rejection rates, and cost breakdown by model. This is relatively easy to set up. Cost analytics are the most critical enterprise metric — track spending by user, model, and team to measure ROI and justify adoption.
The native Console Analytics Dashboard offers a quick, high-level view of accepted lines of code and active users, but lacks business context and downstream impact, limiting its usefulness for a complete ROI picture.




Comments